Working with Document Nodes using UniOffice


Introduction
A common use case when doing an operation within a document is able to get specific content based on the specific type of elements or group the elements by the types and iterate through it.
It requires a lot of work to get a text from paragraph or table element, you need to iterate through paragraphs or tables element down to its children element until you got the run text element.
UniOffice starting with version v.1.16.0 now support extracting document elements as nodes and you can manipulate content on it. The advantage of it is, it keeps the styles and properties intact with the element.
Sometimes the goal of extracting this content is to duplicate or save it separately into a new document. For example, you may wish to extract the content and:
- Make a split to document based on elements —e.g., paragraph or table.
- Rendered a specific portion of a document.
- Duplicate the content in the document many times.
- Work with this content separate from the rest of the document.
Here’s an example of how to replace text and split the document based on style with UniOffice.
// This example shows how Nodes can be used to work generically with document contents to find and copy -
// contents across files. In this example we do:
// 1. Load an input sample document file
// 2. Identify paragraphs with style "heading 1" and use that as a section divider
// 3. Create a new document for each section, and output each section to separate file with names: node-document-i.docx where `i` is the section index.
// In addition we illustrate how to perform some simple replacements that are included in the output files.
package main
import (
"fmt"
"log"
"os"
"github.com/unidoc/unioffice/common/license"
"github.com/unidoc/unioffice/document"
)
func init() {
// Make sure to load your metered License API key prior to using the library.
// If you need a key, you can sign up and create a free one at
// https://cloud.unidoc.io
err := license.SetMeteredKey(os.Getenv("UNIDOC_LICENSE_API_KEY"))
if err != nil {
panic(err)
}
}
func main() {
doc, err := document.Open("sample.docx")
if err != nil {
log.Fatalf("error opening document: %s", err)
}
defer doc.Close()
// Get document element as nodes.
nodes := doc.Nodes()
// Replace text inside nodes based on text.
nodes.ReplaceText("Where can I get some?", "The Title is Replaced")
nodes.ReplaceText("Why do we use it?", "I Am The New Title of Document")
// Find nodes by style name.
nodesByStyle := nodes.FindNodeByStyleName("heading 1")
// Iterate nodes that having style name `heading 1`.
for i, nodeParent := range nodesByStyle {
// Create new document.
newDoc := document.New()
defer newDoc.Close()
fmt.Println("New document will be created")
fmt.Println("Heading:", nodeParent.Text())
nextNodeIndex := i + 1
minIndex := -1
// Iterate through document nodes.
for ni, node := range nodes.X() {
// If the node is having style name `heading 1` (parent node).
if nodeParent.X() == node.X() {
minIndex = ni
}
// If there's next node, break the loop and go to next parentNode.
if len(nodesByStyle) > nextNodeIndex {
if nodesByStyle[nextNodeIndex].X() == node.X() {
minIndex = ni
break
}
}
// Insert node to new document.
if ni >= minIndex && minIndex > -1 {
newDoc.AppendNode(node)
}
}
// Save new doucment.
err := newDoc.SaveToFile(fmt.Sprintf("output/node-document-%d.docx", i))
if err != nil {
log.Fatalf("error while saving file: %v\n", err.Error())
}
}
}
Input File Preview
Page 1

Page 2

Page 3
Output File Preview
node-document-0.docx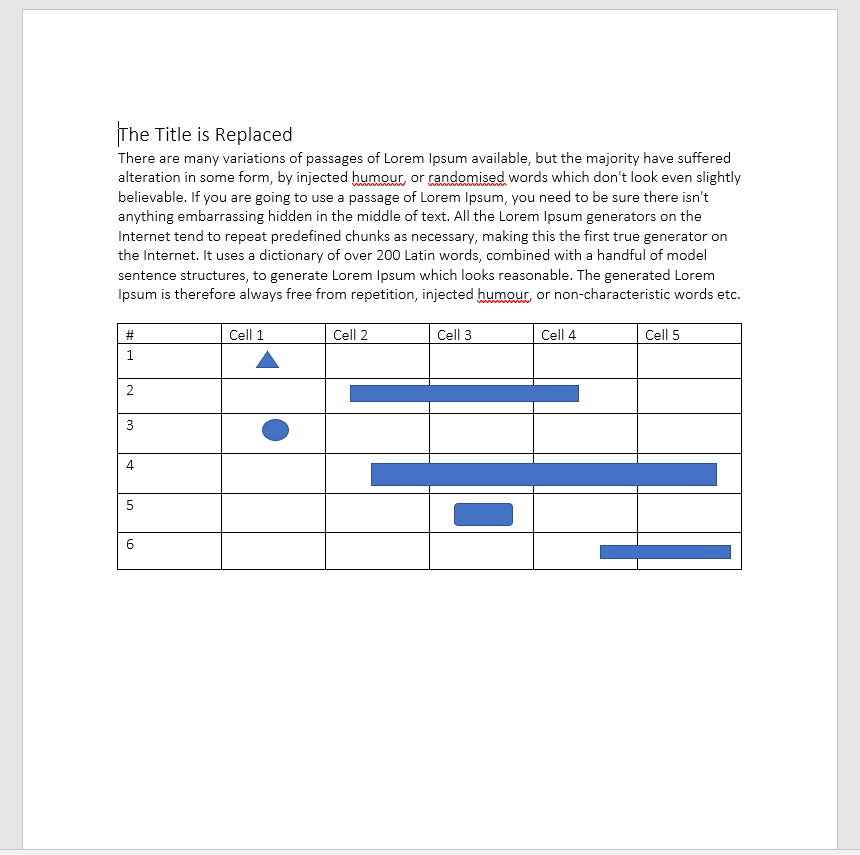
Page 1
node-document-1.docx
Page 1

Page 2
Complete Source Code
https://github.com/unidoc/unioffice-examples/tree/master/document/node-extraction