UniDoc v2 Released

Today we are happy to release UniDoc version 2.0.0, a comprehensive open source PDF library for Golang. In this announcement, we cover some of the key changes with a bit of background how it developed, as well as outlining the main new features and providing references to relevant examples.
Architectural changes
It has been almost a year since we started planning version 2 and created the v2 branch. At that time, as we kept adding more and more functionality to UniDoc v1 we foresaw that the package would grow huge as we supported more and more functionality in PDF. Thus, to make the project more maintainable going forward, we decided to split it up into two packages with separate roles:
unidoc/pdf/core: The core package defines the primitive PDF object types and handles the file reading I/O and parsing the primitive objects.
unidoc/pdf/model: The model package builds on the core package, to represent the PDF as a structured model of the PDF primitive types. It has a reader and a writer to read and process a PDF file based on the structured model. This serves as a basis to perform a number of numerous tasks and can be used to work with a PDF in a medium to high level interface, although it does require an understanding of the PDF format and structure.
In essence, the core package is more or less what we had in v1, except the data models have been moved to model. We have also done extensive work to support more of the data models in the PDF standard.
Advanced processing capability
As an example, one of our customers contacted us regarding a project that they were working on and required converting entire PDF documents from color to grayscale.
For those who do not know the interior of PDF, colors, and colorspaces are very generally defined and many color models exist. In other words, it is pretty darn complex!
In order to support this, we had to add support for PDF functions which also has multiple types (one including a PostScript parser). In addition, we had to read and parse the PDF contents, which are represented in a content stream, which is essentially a stream of commands/operands.
We also added support for Patterns, Shadings, and many more things which are probably not of interest to everyone :) but contact us if you are interested to learn more!
Anyway, the point is: we have added tons of data models for PDF processing, and we are at the point where we can do some quite involved processing and manipulation of PDF contents.
For those who are interested in the grayscale conversion, we have provided some example code that demonstrates conversion of PDF to grayscale: pdf_grayscale_transform.go.
Reporting functionality
A few of our users also requested capability for inserting images and text to PDFs. At the same time, we were working on creating an interactive PDF editor for FoxyUtils.com (available here), which has an Angular frontend, but uses UniDoc in the backend for processing and generating the PDFs.
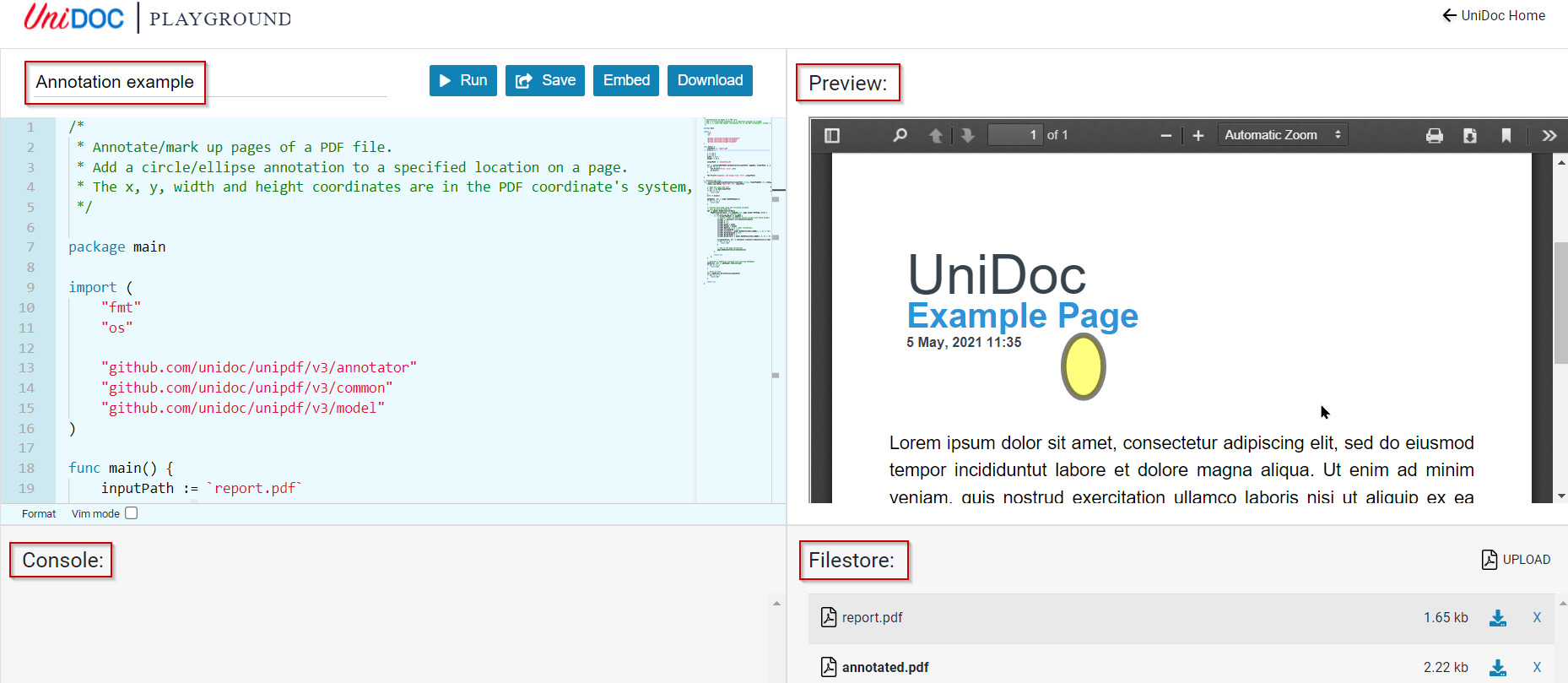
As a result, we added the data models needed for processing images to the project. These models also work when reading an input PDF, for illustration our example pdf_extract_images.go shows how to extract all images from a PDF and image insertion is illustrated in pdf_add_image_to_page.go.
At this point, we had a lot of cool capabilities, but simple tasks like creating a PDF with an image required pretty complex code and understanding of PDF.
Most people don’t know the command for creating an image “/Image1 Do” in PDF… or others and would probably like to avoid reading through the extensive PDF standard to figure out how to do a simple task. Thus, we wanted to hide away this complexity and create a higher level API to access the common tasks for PDF creation. As a result, we created a separate package called creator for handling this:
- unidoc/pdf/creator: The PDF creator makes it easy to create new PDFs or modify existing ones. It can also enable loading a template PDF, adding text/images and generating an output PDF. It can be used to add text, images, and generate text and graphical reports. It is designed with simplicity in mind, with the goal of making it easy to create reports without needing any knowledge about the PDF format or specifications.
As we worked on the creator we realized that it could be a cool tool for creating PDF reports etc. We are still working on improving the creator, but we already have a few key components:
The Drawable interface. Each visual element needs to implement the Drawable interface and have functionality to draw the component and handle wrapping over multiple pages in some cases.
Paragraph. The paragraph is simply text which can wrap over multiple lines and pages (unless wrapping is not enabled). The text has a specified font, size, color, and other style properties.
Image. Can be loaded from file and either drawn to a specific position (absolute) or in relative mode in context.
Chapter and Subchapter: Used for arranging paragraphs and other drawables into chapters and subchapters.
Table. Can be used for arranging Drawables into a grid.
The goal with the creator is to be able to create good-looking reports without a ton of effort, with simple and understandable code.
We have created an example to illustrate the PDF creation capability. The source code for the example pdf_report.go and the resulting generated PDF is available here: unidoc-report.pdf.
Example highlights
We have prepared a fairly extensive set of examples for getting started with UniDoc. While we feel they are all very exciting and encourage everyone to take a look, we would like to highlight a few of those that may be of most benefit to the bulk of our users:
PDF report generation with a simple high level API interface
- Generation of a basic report pdf_report.go
Inserting images, drawing on existing PDFs:
- Insert image: pdf_add_image_to_page.go
- Draw line on page: pdf_draw_line.go
Barcode generation
- Generating and adding QR code: pdf_add_qr_code.go
- Generating and adding barcode: pdf_add_barcode.go
Basic operations:
- Merging pdfs pdf_merge.go
- Splitting pdfs pdf_split.go
- Protecting pdf_protect.go
- Unlocking pdf_unlock.go
The full set has many more examples for specific tasks. If you have ideas for new examples, let us know!
License simplification
UniDoc is dual-licensed under AGPLv3 and a commercial license available to allow use in closed source and non-AGPLv3 products.
When we first released UniDoc, it was released under AGPLv3 with a few additional terms. Thanks to our interaction with Cathal Garvey, we determined that the additional terms were unnecessary and some in a gray area. As a result, we changed to standard AGPLv3 without any additional constraints.
We want the project to be open source and anyone should be able to read and try the code. Developers can try UniDoc and see if it fits their needs and test if it works in a production environment. When going live with UniDoc in a closed source product (or non-AGPLv3 licensed), the commercial license is needed.
Our pricing model is pretty simple and a Business Unlimited License allows unlimited developers/servers and includes support. The support can be to make an example for performing a certain task or even adding features that are missing in UniDoc and/or priorities bug fixes.
The development and maintenance of UniDoc is financed by those fees, so these fees are what keeps the engine running.
Conclusion
In summary, UniDoc v2 is finally out and is on the UniDoc master branch now (finally!). It has many new features, and we suggest you go get it and test out our examples.
If you have any questions or need an example that is not provided, please contact us or email us via [email protected]. If you find a bug, you can file an issue on GitHub or shoot us an email.