UniAI Introduction: Step-by-Step Getting Started Guide


By the growth of AI development and research, now AI models can be used to automatically convert messy text, logs, or pages into structured JSON data and to generate synthetic tabular datasets for analytics, testing, or search/SEO markup at scale.
However, the main challenges are schema design, and when it comes to PDF, the other problem is the tools that can read or extract the PDF content itself. UniAI offers a powerful solution to these hurdles.
What is UniAI?
UniAI is our new cloud-based API designed to make working with documents smarter and easier. At its core, UniAI takes a PDF file, processes it with our trusted UniPDF engine, and then applies advanced AI to extract structured JSON data.
Instead of worrying about the document’s layout, formatting, or OCR preprocessing, you simply upload a PDF and receive clean, ready-to-use JSON data. For invoices, UniAI can automatically detect fields like totals, invoice numbers, and dates.
For resumes, it can parse names, contact details, skills, and experience into structured data for HR or recruitment systems. UniAI eliminates the need for manual data entry or building custom parsers for every new document format.
How to Get Started with UniAI
You can start with UniAI in just a few steps.
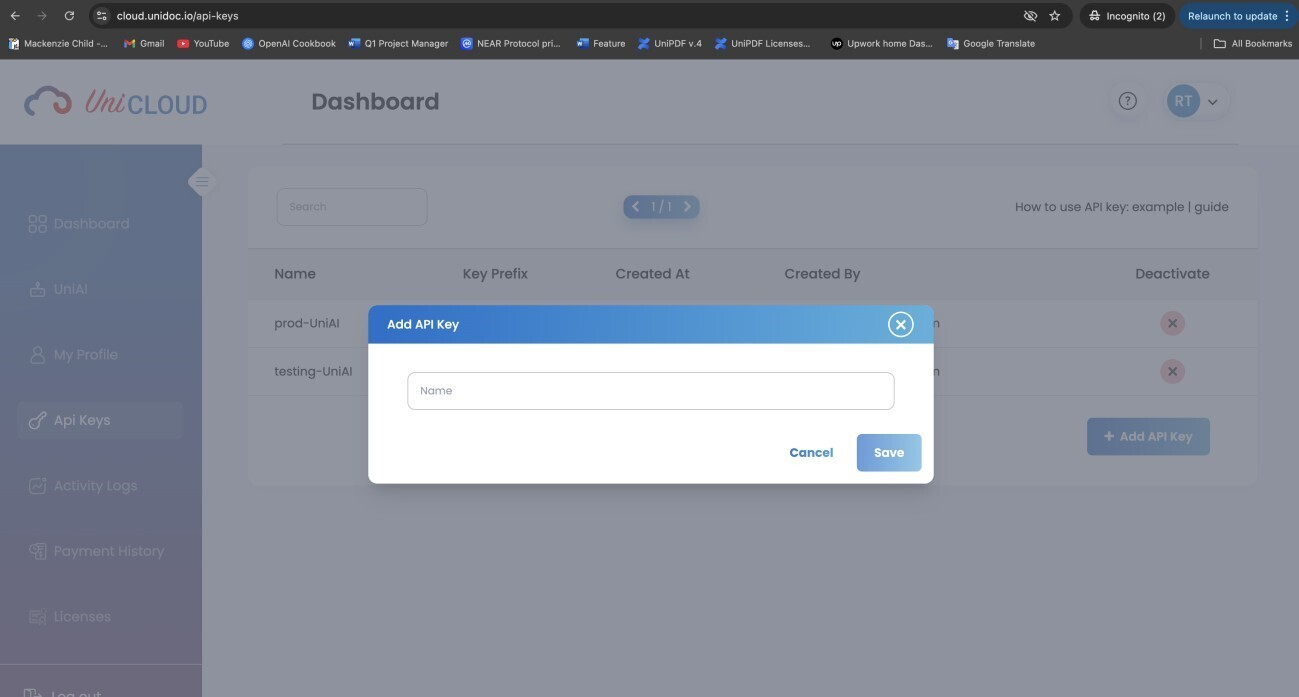
Step 1: Create UniCloud API key
To get started, you first need to create an account in UniCloud. If you don’t have one yet, sign up for UniCloud. Once you’ve logged in, navigate to the API Keys section of the UniCloud dashboard. From there, you can easily generate a new API key, which will be required for authentication when using UniDoc services.
Step 2: Prepare Your API Request
You need CURL or similar app that can access the endpoint and send body request
The UniAI accessed through API endpoint and here we show how to access it through curl.
Our UniAI endpoint can extract 2 types of documents, invoices and resumes (cv).
Base endpoint:
https://cloud.unidoc.io/api/uniai/extract/:type
It is required the UniCloud API Key, and accept body parameters of
File which will be your PDF file.
If your PDF file has a complex structure or is scanned, you need to set
is_scannedto true.
Replace :type with:
invoice - for invoice processing
resume - for resume processing
For Invoice Processing:
Use this endpoint to process invoices.
curl -X POST https://cloud.unidoc.io/api/uniai/extract/invoice -H "X-API-KEY: $UNIDOC_API_KEY" -F "file=@Desktop/invoice-test.pdf"
For Resume Processing:
Use this endpoint to process resume.
curl -X POST https://cloud.unidoc.io/api/uniai/extract/resume -H "X-API-KEY: $UNIDOC_API_KEY" -F "file=@Desktop/cv.pdf"
This is the curl example for simple invoice.
curl -X POST https://cloud.unidoc.io/api/uniai/extract/invoice -H "X-API-KEY: $UNIDOC_LICENSE_API_KEY" -F "file=@/Documents/your_invoice.pdf"
JSON Output
{
"invoice_number": "506617438",
"invoice_date": "2025-03-01",
"due_date": "2025-03-01",
"seller": {
"name": "DigitalOcean LLC",
"address": "105 Edgeview Drive, Suite 425\nBroomfield, CO, 80021",
"vat_id": "136267",
"id_number": "621119-9900"
},
"customer": {
"name": "UniDoc do:team:6ebf86a1ef50a0fac7508fff481469a",
"email": "[email protected]",
"address": "Bardastadir 71\nReykjavik, Reykjavik, 112\nICELAND"
},
"line_items": [
{
"category": "Product Usage Charges",
"item_description": "Droplets Hours Start End",
"details": [
{
"item": "db-01.com (s-2vcpu-4gb)",
"quantity": 672,
"unit_price": null,
"amount": 24.0
},
{
"item": "u01.unidoc.io (s-1vcpu-2gb)",
"quantity": 672,
"unit_price": null,
"amount": 12.0
},
{
"item": "db.unidoc.io (s-2vcpu-4gb)",
"quantity": 672,
"unit_price": null,
"amount": 24.0
},
{
"item": "uni.unidoc.io (s-4vcpu-8gb)",
"quantity": 672,
"unit_price": null,
"amount": 48.0
}
]
},
{
"category": "Product Usage Charges",
"item_description": "Kubernetes Clusters Hours Start End",
"details": [
{
"item": "cluster",
"quantity": 672,
"unit_price": null,
"amount": 60.0
},
{
"item": "cloud-cluster",
"quantity": 672,
"unit_price": null,
"amount": 60.0
}
]
},
{
"category": "Product Usage Charges",
"item_description": "Spaces Hours Start End",
"details": [
{
"item": "Spaces ($5/mo 250GiB storage & 1TiB bandwidth)",
"quantity": 672,
"unit_price": null,
"amount": 5.0
}
]
},
{
"category": "Product Usage Charges",
"item_description": "Volumes Hours Start End",
"details": [
{
"item": "foxydb-db (nyc1) - 100.00GB Volume",
"quantity": 672,
"unit_price": null,
"amount": 10.0
},
{
"item": "foxydb-nfs (nyc1) - 100.00GB Volume",
"quantity": 672,
"unit_price": null,
"amount": 10.0
},
{
"item": "volume-nyc1-01 (nyc1) - 100.00GB Volume",
"quantity": 672,
"unit_price": null,
"amount": 10.0
}
]
},
{
"category": "Product Usage Charges",
"item_description": "Droplet Backups Hours Start End",
"details": [
{
"item": "db.foxyutils.com (Weekly Backup Services)",
"quantity": 4,
"unit_price": null,
"amount": 4.8
},
{
"item": "db.unidoc.io (Weekly Backup Services)",
"quantity": 4,
"unit_price": null,
"amount": 4.8
},
{
"item": "uni.unidoc.io (Weekly Backup Services)",
"quantity": 4,
"unit_price": null,
"amount": 9.6
},
{
"item": "uni01.unidoc.io (Weekly Backup Services)",
"quantity": 4,
"unit_price": null,
"amount": 2.4
}
]
}
],
"subtotal": {
"amount": 284.6,
"currency": "$"
},
"taxes": [
{
"type": "VAT Iceland",
"amount": 68.3,
"currency": "$"
}
],
"total": {
"amount": 352.9,
"currency": "$"
},
"notes": "Final invoice for the February 2025 billing period"
}
The response comes back in structured JSON. It can include the vendor name, invoice date, line items and totals. This makes it easy to pass the data into other tools or store it in your own system.
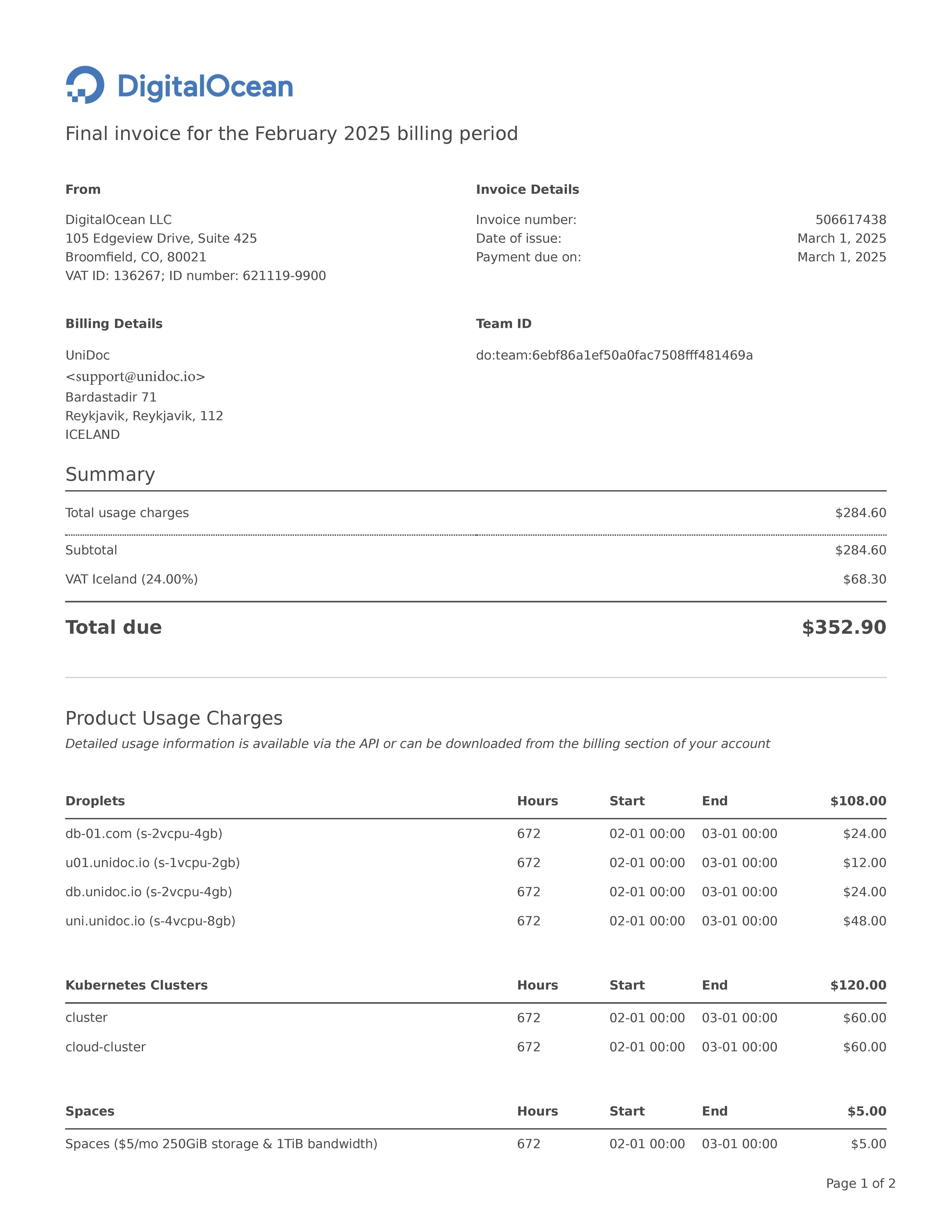
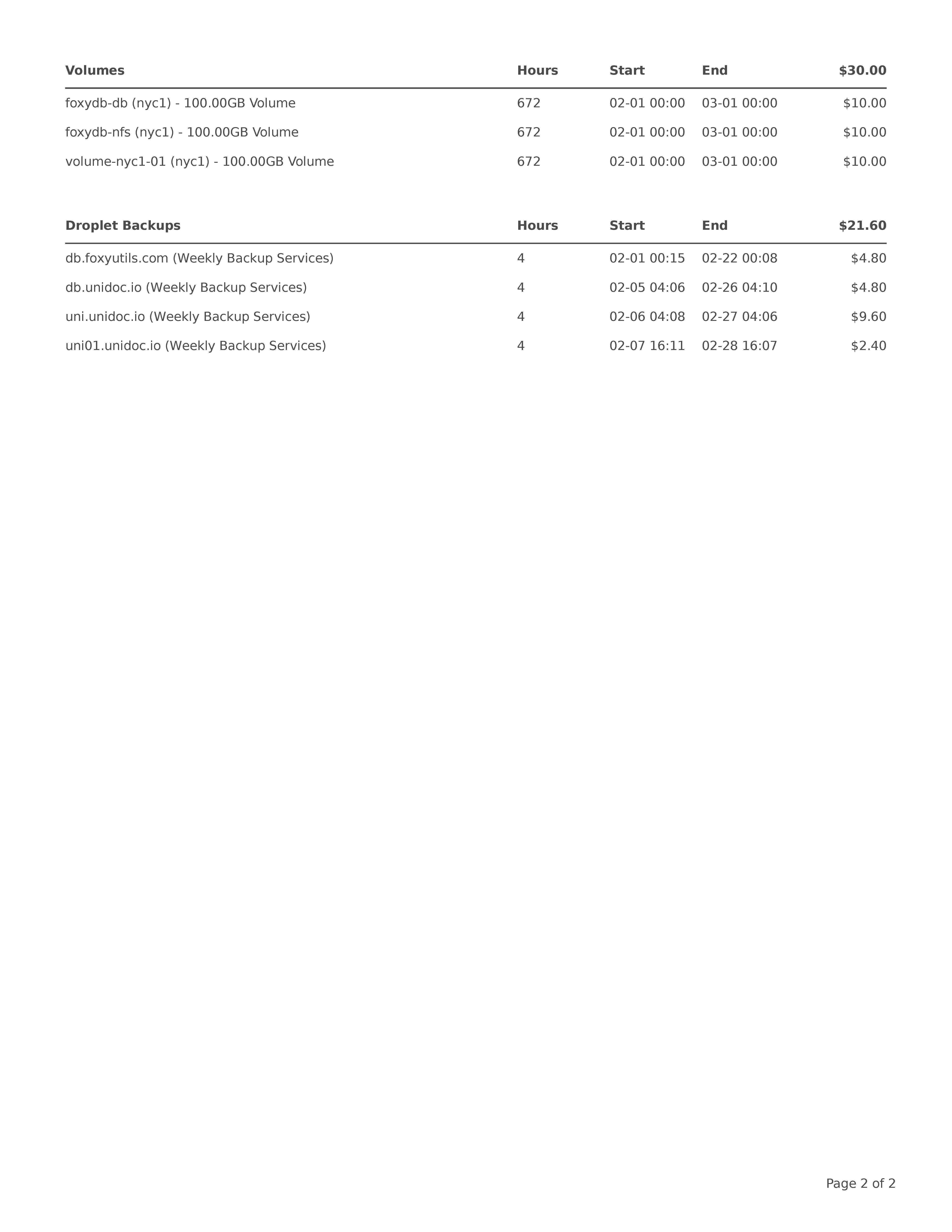
What This Means for Your Business:
Instead of spending 30+ minutes manually entering this invoice data, UniAI extracts everything in under 10 seconds with 100% accuracy.
Multiply this by hundreds or thousands of invoices, and you’re looking at:
Massive time savings
Eliminated human errors
Instant data integration into your accounting systems
Better cash flow management with faster processing
Why UniAI?
UniAI offers key advantages for efficient data extraction:
The combination of UniPDF and Gemini AI model ensures robust processing and intelligent data recognition.
It provides a ready-to-use API endpoint with a clean JSON response, simplifying integration.
The system is optimized through prompt engineering and testing to ensure efficiency in response time and token usage.
It saves time & money by automating extraction of structured data from PDFs, reducing manual effort and errors.
Easy to integrate, its simple REST API works with your existing workflows in minutes.
It is scalable & predictable, allowing you to pay only for the pages you process.
Built on UniPDF, it is powered by our trusted PDF engine, ensuring reliability and quality text extraction.
The Requirements
To utilize UniAI, the following are required:
UniCloud API key
CURL or a similar app that can access the endpoint and send body requests
Conclusion
UniAI is built to remove the hardest part of invoice work. It reads PDFs and gives back clean JSON, so you do not waste time on manual entry.
By using it your team gets more accurate data, faster results and less risk of error.
Ready to see it in action? Try UniAI today at the UniDoc official site.
Have questions? Need help getting started? Contact us to discuss your specific use case and get personalized assistance from our team.