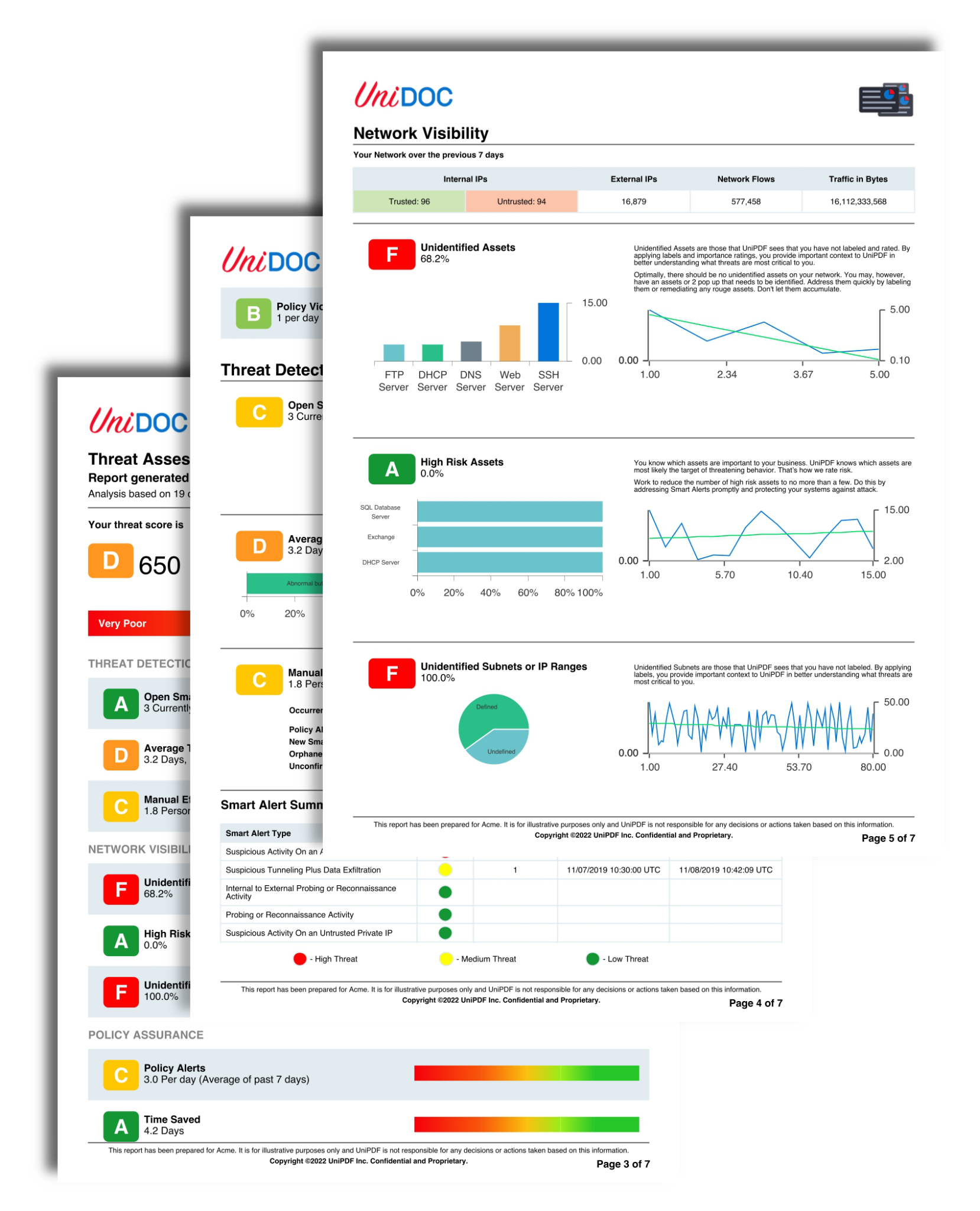
Filling and Flattening PDF Forms in Go

Introduction
PDF forms are a convenient tool for gathering and storing information about your customers, users, or employees. For example, you can collect data from your website and insert it into PDF forms by injecting values from JSON files to create everlasting PDFs, i.e. PDF files that have been flattened and made uneditable.
Go is often called the language of the cloud (for good reasons) and enables you to create powerful programs and deploy as a single independent binary for convenient deployment in minimal Docker containers or otherwise. It is perfect for microservices and its blazing speed enables you to beat the rest of the class. Thus by processing PDFs in Go gives you fantastic performance, cloud-native applications, and simplicity, much higher security compared to C-based applications.
You might have applications downloadable as PDF forms from your website that users could fill in and send via email or collect the data through forms on your website. Each application you could store for processing and then create a flattened copy which is essentially the form with the data filled out, but has been flattened where the form values have been embedded into the content and become an uneditable part of the document.
The next step would be to flatten the PDF form to ensure the immutability of the information. You can now archive the PDFs for your records and email a copy to your customer, user or employee. This is one use case of how you can easily fill pdf forms, and flatten PDF forms to smoothen your business processes.
Outline
In this article we will cover the key aspects of handling PDF forms, including:
- Introduction covering what form PDF files are and what flattening is
- Why choose a Golang library for PDF processing needs?
- Create a fillable PDF form on top of a template PDF
- Fill a PDF form programmatically via input data in JSON format
- Flatten a filled PDF and create an uneditable output PDF with no forms
- Fill and flatten in one step as often required.
What is a PDF form?
PDF (Portable Document Format) forms are digital documents that can be filled out electronically. PDF forms allow users to enter data into predefined fields, checkboxes, and other input areas, making it easy to collect information from a large number of users in a standardized format.
PDF forms are commonly used for a variety of purposes, including:
- Online surveys and questionnaires
- Job applications and employee onboarding forms
- Contact forms on websites
- Order forms for products and services
- Insurance claims and other legal documents
- Tax forms and other government documents
PDF forms offer several advantages over paper-based forms, including faster processing times, reduced paper waste, and increased accuracy of data. They also allow for easier data sharing and analysis, as the information collected can be easily exported into other formats for use in spreadsheets and databases.
In addition, PDF forms can be filled out and signed electronically, eliminating the need for physical signatures and making it easier to collect and store legally binding documents. Overall, PDF forms provide a convenient and efficient way to collect and process information in a digital format.
What is PDF Form Flattening?
PDF form flattening is the process of converting an interactive PDF form into a static PDF file with all form fields and annotations permanently merged into the page content. When a PDF form is flattened, users can no longer interact with the form fields or modify the information entered into the fields. Instead, the form fields become part of the PDF page and can no longer be edited or deleted.
PDF form flattening offers several benefits, including:
- Data Security: Flattened PDF forms are less susceptible to unauthorized modification or tampering since form fields are merged with the page content.
- Compatibility: Flattened PDF forms can be viewed and printed on any device or platform without requiring special software or plugins to view and interact with form fields.
- Preservation: Flattening PDF forms can preserve the appearance and layout of the original form, making it easier to archive and access form data in the future.
- Compliance: Some industries or regulatory bodies require flattened PDF forms for legal or record-keeping purposes.
Overall, PDF form flattening can help ensure the security and accuracy of form data, improve compatibility across devices and platforms, and facilitate compliance with legal and regulatory requirements.
Why use Go for filling and flattening PDF files?
There are several reasons why one might choose to use Go for filling and flattening PDF files. Go is a cross-platform programming language with robust support for PDF processing, making it a good choice for working with PDF files. Go’s efficient memory management and concurrent programming support can also help improve performance and reduce processing times.
In addition, Go is well-suited for building small and efficient Docker container images that can be easily deployed in a Kubernetes environment. Go applications can be compiled into small, statically-linked binary files that contain everything the application needs to run, reducing storage and bandwidth requirements. Go’s fast compilation and strong dependency management system also make it easy to automate the build process and generate new container images on demand.
Furthermore, Go’s support for concurrency and parallelism can help containerized PDF form filling and flattening applications handle high levels of traffic and workload, improving their performance and scalability in a Kubernetes environment. Overall, Go’s combination of PDF processing capabilities, efficient containerization, and strong support for concurrency and parallelism make it a good choice for building PDF form filling and flattening applications that can be easily deployed and scaled in a Kubernetes environment.
Creating a fillable PDF form on top of a simple template PDF file
In many cases you will have your forms already prepared. They might be created using Adobe Acrobat or prepared by your designer in more fancy design software and form fields added on top of that with Adobe Acrobat or other software.
Let’s look at what to do if we don’t have any form prepared. Let’s start by preparing a simple PDF file with MS Word with some fields and export it to PDF. Figure 1 shows the resulting PDF file, where key entries are on the left such as “Full Name” followed by a blank where the value is intended to be entered, etc.

Figure 1: Simple PDF form template with visible fields
This kind of PDF is purely flat, meaning that if you open it in a PDF viewer such as Adobe Reader or any web browser, you can only see the text, not insert any values.
To convert this into a fillable PDF form, we need to add some data to the PDF which indicates what fields are in the document, and where they are (i.e. in PDF space coordinates). We just need to define the coordinates of the rectangles where the input field should be present and then let the annotator package of UniPDF take care of building the fields on your PDF document.
We do this by defining
- Name. Each field has a unique name so that it can be referenced directly. The name often indicates what the field represents.
- Position (Rect). The bounding box representing the field area denoted by a rectangle in PDF coordinates.
- Value. The value of the field (if filled). This varies depending on field type. For example for a checkbox it can be true/false (representing checked/unchecked). A textbox would have the value as a simple string and a choice field (dropdown) would have a selected string from a list of options.
For example:
// textFieldsDef is a list of text fields to add to the form.
// The Rect field specifies the coordinates of the field.
var textFieldsDef = []struct {
Name string
Rect []float64
}{
{Name: "full_name", Rect: []float64{123.97, 619.02, 343.99, 633.6}},
{Name: "address_line_1", Rect: []float64{142.86, 596.82, 347.3, 611.4}},
{Name: "address_line_2", Rect: []float64{143.52, 574.28, 347.96, 588.86}},
{Name: "age", Rect: []float64{95.15, 551.75, 125.3, 566.33}},
{Name: "city", Rect: []float64{96.47, 506.35, 168.37, 520.93}},
{Name: "country", Rect: []float64{114.69, 483.82, 186.59, 498.4}},
}
// checkboxFieldDefs is a list of checkboxes to add to the form.
var checkboxFieldDefs = []struct {
Name string
Rect []float64
Checked bool
}{
{Name: "male", Rect: []float64{113.7, 525.57, 125.96, 540.15}, Checked: true},
{Name: "female", Rect: []float64{157.44, 525.24, 169.7, 539.82}, Checked: false},
}
// choiceFieldDefs is a list of comboboxes to add to the form with specified options.
var choiceFieldDefs = []struct {
Name string
Rect []float64
Options []string
}{
{
Name: "fav_color",
Rect: []float64{144.52, 461.61, 243.92, 476.19},
Options: []string{"Black", "Blue", "Green", "Orange", "Red", "White", "Yellow"},
},
}
Then we create the fields for each field type. For instance, in the case of text fields, we create the TextField and add to the page annotations:
for _, fdef := range textFieldsDef {
opt := annotator.TextFieldOptions{}
textf, err := annotator.NewTextField(page, fdef.Name, fdef.Rect, opt)
if err != nil {
panic(err)
}
*form.Fields = append(*form.Fields, textf.PdfField)
page.AddAnnotation(textf.Annotations[0].PdfAnnotation)
}
The process is similar for the other field types as can be seen in the full Playground code example below. Finally, the output PDF is written out with
pdfWriter.SetForms(form)
return pdfWriter.WriteToFile(outputPath)
and the output PDF file can be seen in Figure 2 below. The full code snippet follows with a Playground example that can be modified and run in our playground. It can be seen that the fields now have inputs where values can be inserted in the Viewer.
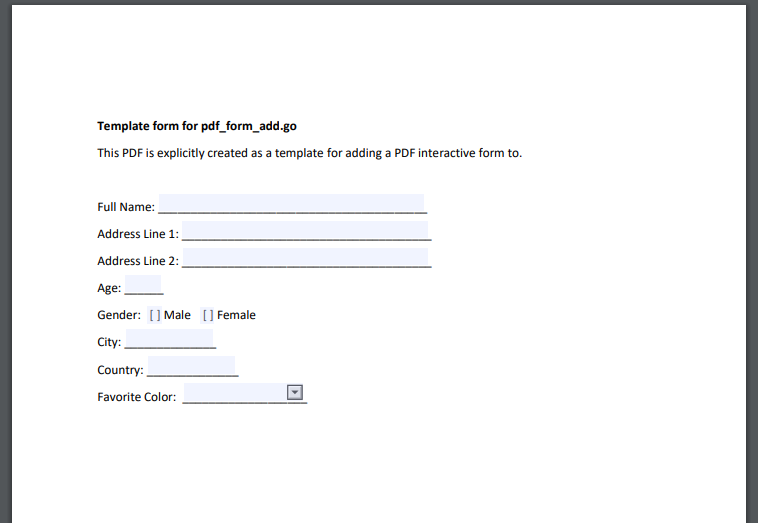
Figure 2: PDF form created on top of the template PDF file.
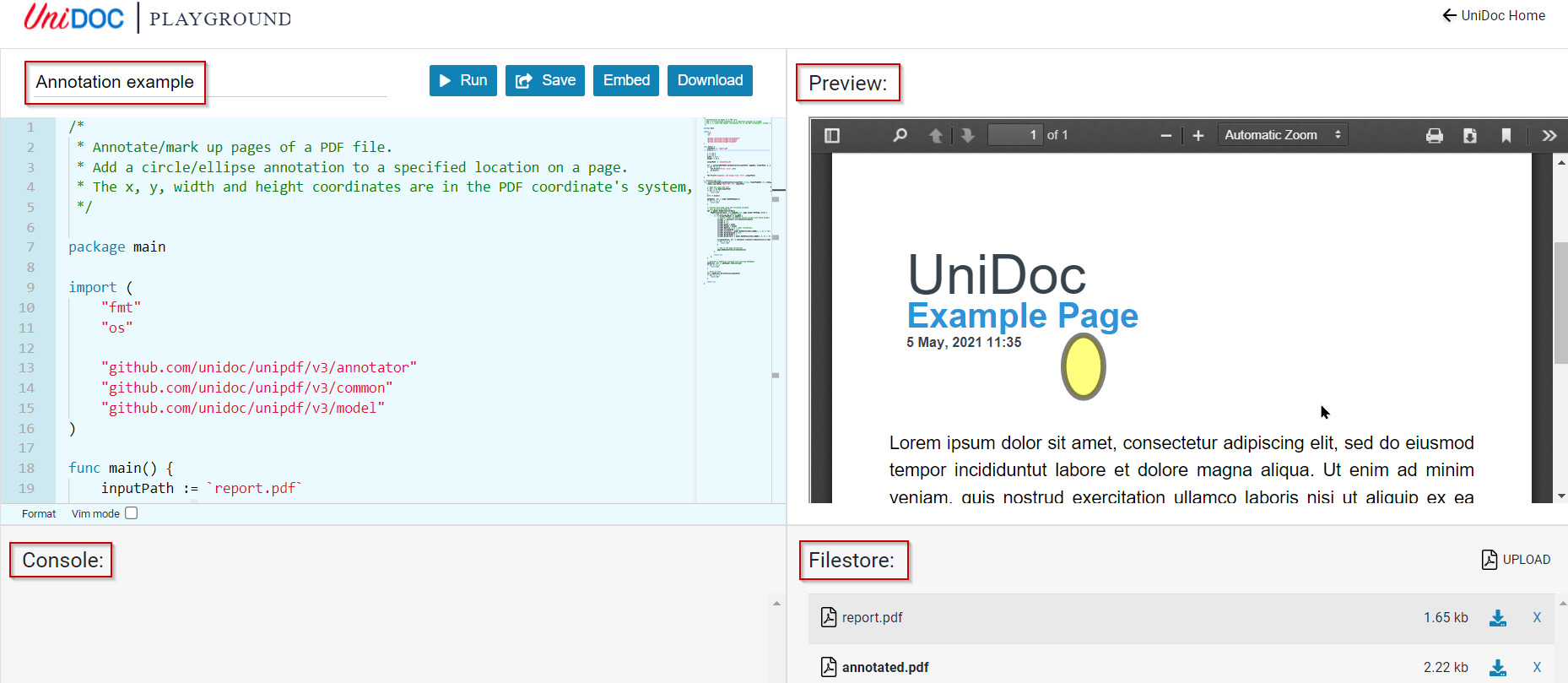
Playground Example - Creating a PDF form
The full Playground example for creating a form on top of a simple PDF template is shown below.
/*
* Create and apply a new form to an existing PDF.
* The example shows how to load template1.pdf and add an interactive form to it and save it
* as template1_with_form.pdf.
*
* Run as: go run pdf_form_add.go
*/
package main
import (
"fmt"
"os"
"github.com/unidoc/unipdf/v3/annotator"
"github.com/unidoc/unipdf/v3/model"
)
func main() {
inputPath := `template1.pdf`
outputPath := `template1_with_form.pdf`
err := addFormToPdf(inputPath, outputPath)
if err != nil {
fmt.Printf("Failed to add form: %#v\n", err)
os.Exit(1)
}
fmt.Printf("Success, output in %s\n", outputPath)
}
// addFormToPdf adds the form to the PDF specified by `inputPath` and outputs to `outputPath`.
func addFormToPdf(inputPath string, outputPath string) error {
// Read the input pdf file.
f, err := os.Open(inputPath)
if err != nil {
return err
}
defer f.Close()
pdfReader, err := model.NewPdfReader(f)
if err != nil {
return err
}
var form *model.PdfAcroForm
// Generate a new AcroForm instead of copying from the source PDF.
opt := &model.ReaderToWriterOpts{
SkipAcroForm: true,
PageProcessCallback: func(pageNum int, page *model.PdfPage) error {
if pageNum == 1 {
form = createForm(page)
}
return nil
},
}
// Generate a PdfWriter instance from existing PdfReader.
pdfWriter, err := pdfReader.ToWriter(opt)
if err != nil {
return err
}
// Set new AcroForm.
err = pdfWriter.SetForms(form)
if err != nil {
return err
}
return pdfWriter.WriteToFile(outputPath)
}
// textFieldsDef is a list of text fields to add to the form. The Rect field specifies the coordinates of the
// field.
var textFieldsDef = []struct {
Name string
Rect []float64
}{
{Name: "full_name", Rect: []float64{123.97, 619.02, 343.99, 633.6}},
{Name: "address_line_1", Rect: []float64{142.86, 596.82, 347.3, 611.4}},
{Name: "address_line_2", Rect: []float64{143.52, 574.28, 347.96, 588.86}},
{Name: "age", Rect: []float64{95.15, 551.75, 125.3, 566.33}},
{Name: "city", Rect: []float64{96.47, 506.35, 168.37, 520.93}},
{Name: "country", Rect: []float64{114.69, 483.82, 186.59, 498.4}},
}
// checkboxFieldDefs is a list of checkboxes to add to the form.
var checkboxFieldDefs = []struct {
Name string
Rect []float64
Checked bool
}{
{Name: "male", Rect: []float64{113.7, 525.57, 125.96, 540.15}, Checked: true},
{Name: "female", Rect: []float64{157.44, 525.24, 169.7, 539.82}, Checked: false},
}
// choiceFieldDefs is a list of comboboxes to add to the form with specified options.
var choiceFieldDefs = []struct {
Name string
Rect []float64
Options []string
}{
{
Name: "fav_color",
Rect: []float64{144.52, 461.61, 243.92, 476.19},
Options: []string{"Black", "Blue", "Green", "Orange", "Red", "White", "Yellow"},
},
}
// createForm creates the form and fields to be placed on the `page`.
func createForm(page *model.PdfPage) *model.PdfAcroForm {
form := model.NewPdfAcroForm()
// Add ZapfDingbats font.
zapfdb := model.NewStandard14FontMustCompile(model.ZapfDingbatsName)
form.DR = model.NewPdfPageResources()
form.DR.SetFontByName(`ZaDb`, zapfdb.ToPdfObject())
for _, fdef := range textFieldsDef {
opt := annotator.TextFieldOptions{}
textf, err := annotator.NewTextField(page, fdef.Name, fdef.Rect, opt)
if err != nil {
panic(err)
}
*form.Fields = append(*form.Fields, textf.PdfField)
page.AddAnnotation(textf.Annotations[0].PdfAnnotation)
}
for _, cbdef := range checkboxFieldDefs {
opt := annotator.CheckboxFieldOptions{}
checkboxf, err := annotator.NewCheckboxField(page, cbdef.Name, cbdef.Rect, opt)
if err != nil {
panic(err)
}
*form.Fields = append(*form.Fields, checkboxf.PdfField)
page.AddAnnotation(checkboxf.Annotations[0].PdfAnnotation)
}
for _, chdef := range choiceFieldDefs {
opt := annotator.ComboboxFieldOptions{Choices: chdef.Options}
comboboxf, err := annotator.NewComboboxField(page, chdef.Name, chdef.Rect, opt)
if err != nil {
panic(err)
}
*form.Fields = append(*form.Fields, comboboxf.PdfField)
page.AddAnnotation(comboboxf.Annotations[0].PdfAnnotation)
}
return form
}
Listing fields in a PDF document
When you receive a PDF application form from the Sales department and are instructed to fill it with customer information from a database, you need to know what fields are in the PDF and how to match it to customer information.
Powerful PDF editors such as Adobe Acrobat can show the field information visually, including the field names and properties such as default font, font size, etc.
It can also be convenient to collect the field information programmatically. When working with field data in UniPDF, it is particularly convenient to express the field information as JSON. In fact, it is straightforward to get the full field information from a PDF with a form. The basic code for this is simply:
fdata, _ := fjson.LoadFromPDFFile("template1_with_form.pdf")
jsonData, _ := fdata.JSON()
fmt.Printf("%s\n", jsonData)
The output for this, for instance on the PDF form shown in Figure 2 is:
[
{
"name": "full_name",
"value": ""
},
{
"name": "address_line_1",
"value": ""
},
{
"name": "address_line_2",
"value": ""
},
{
"name": "age",
"value": ""
},
{
"name": "city",
"value": ""
},
{
"name": "country",
"value": ""
},
{
"name": "male",
"value": "Off",
"options": ["Off", "Yes"]
},
{
"name": "female",
"value": "Off",
"options": ["Off", "Yes"]
},
{
"name": "fav_color",
"value": ""
}
]
So this gives pretty clear indication on what fields we have and what form types and values we can enter. We will use this below and fill into those fields programmatically and finally flattening the PDF.
The full Playground example for this can be found below where it can be Run and the output seen.
Playground Example - Listing fields in PDF form
/*
* Fill PDF form via JSON input data and flatten the output PDF.
*
* Run as: go run pdf_form_fill_json.go input.pdf fill.json [output.pdf].
*/
package main
import (
"fmt"
"os"
"github.com/unidoc/unipdf/v3/annotator"
"github.com/unidoc/unipdf/v3/fjson"
"github.com/unidoc/unipdf/v3/model"
)
// Example of filling PDF formdata with a form.
func main() {
var (
inputPath string
filljsonPath string
outputPath string
)
inputPath = "template1_with_form.pdf"
filljsonPath = ""
outputPath = ""
// Output path not specified: Export list of fields and data as JSON format.
if len(outputPath) == 0 {
fdata, err := fjson.LoadFromPDFFile(inputPath)
if err != nil {
fmt.Printf("Error: %v\n", err)
os.Exit(1)
}
if fdata == nil {
fmt.Printf("No data\n")
return
}
fjson, err := fdata.JSON()
if err != nil {
fmt.Printf("Error: %v\n", err)
os.Exit(1)
}
fmt.Printf("%s\n", fjson)
return
}
err := fillFields(inputPath, filljsonPath, outputPath)
if err != nil {
fmt.Printf("Error: %v\n", err)
os.Exit(1)
}
fmt.Printf("Success, output written to %s\n", outputPath)
}
// fillFields loads field data from `jsonPath` and used to fill in form data in `inputPath` and outputs
// as PDF in `outputPath`. The output PDF form is flattened.
func fillFields(inputPath, jsonPath, outputPath string) error {
fdata, err := fjson.LoadFromJSONFile(jsonPath)
if err != nil {
return err
}
f, err := os.Open(inputPath)
if err != nil {
return err
}
defer f.Close()
pdfReader, err := model.NewPdfReader(f)
if err != nil {
return err
}
// Populate the form data.
err = pdfReader.AcroForm.Fill(fdata)
if err != nil {
return err
}
// Flatten form.
fieldAppearance := annotator.FieldAppearance{OnlyIfMissing: true, RegenerateTextFields: true}
// NOTE: To customize certain styles try:
// style := fieldAppearance.Style()
// style.CheckmarkGlyph = "a22"
// style.AutoFontSizeFraction = 0.70
// fieldAppearance.SetStyle(style)
//
// or for specifying a full set of appearance styles:
// fieldAppearance.SetStyle(annotator.AppearanceStyle{
// CheckmarkGlyph: "a22",
// AutoFontSizeFraction: 0.70,
// FillColor: model.NewPdfColorDeviceGray(0.8),
// BorderColor: model.NewPdfColorDeviceRGB(1, 0, 0),
// BorderSize: 2.0,
// AllowMK: false,
// })
err = pdfReader.FlattenFields(true, fieldAppearance)
if err != nil {
return err
}
// Generate a PdfWriter instance from existing PdfReader.
pdfWriter, err := pdfReader.ToWriter(nil)
if err != nil {
return err
}
// Write to file.
err = pdfWriter.WriteToFile(outputPath)
return err
}
To run the Play, click “View/Run” on the UniDoc Playground. Then click “▶ Run”, then observe the output in the “Console:” output window.
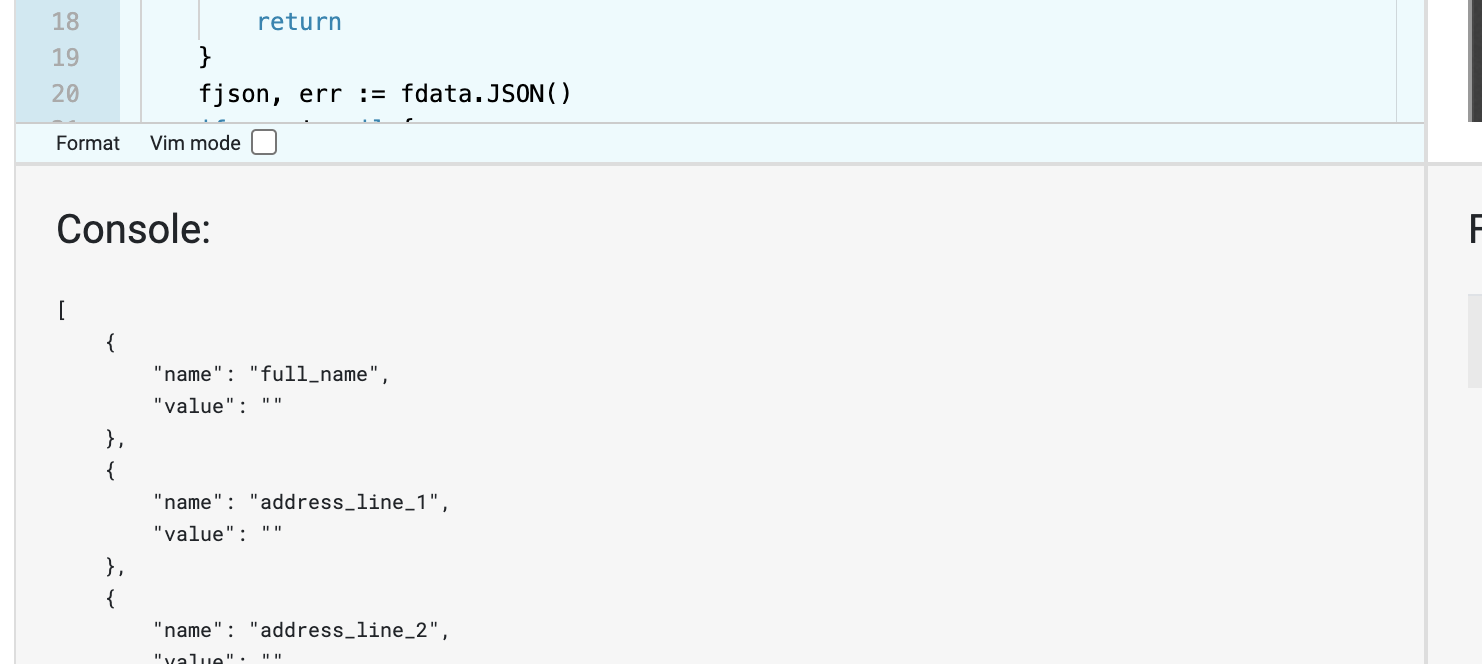
Playground console output
Working with the playground is a convenient place to try the library, even without needing to sign up for a free license key.
Fill PDF form in golang
Filling a PDF form involves inserting values into the fields. In an editor, it will look like a person had entered values into the field and saved. The values can still be edited and changed.
For an automated process, where values are collected from the user or a database and injected into the PDF, there is a need to perform filling of values programmatically.
The basic method to insert and write out a filled PDF form is as the following code shows:
// Load the form data to be inserted (key/values) from JSON file.
fdata, \_ := fjson.LoadFromJSONFile(`data.json`)
// Load the PDF.
pdfReader, \_ := model.NewPdfReaderFromFile(`form.pdf`, nil)
// Options for default appearance of contents.
fieldAppearance := annotator.FieldAppearance{OnlyIfMissing: true, RegenerateTextFields: true}
// Populate the form data.
pdfReader.AcroForm.FillWithAppearance(fdata, fieldAppearance)
// Write out filled PDF.
pdfWriter, \_ := pdfReader.ToWriter(nil)
pdfWriter.WriteToFile("form_filled.pdf")
Note we used FillWithAppearance rather than simply Fill to generate appearance based on the values we are setting. In most cases the default appearance is shown, but most viewers can generate appearances based on the values, if the values are edited. Further things like fonts, can be customized as well.
The output file form_filled.pdf looks as follows afterward (Figure 3). We can clearly see that the values have been filled, but the form is still editable.
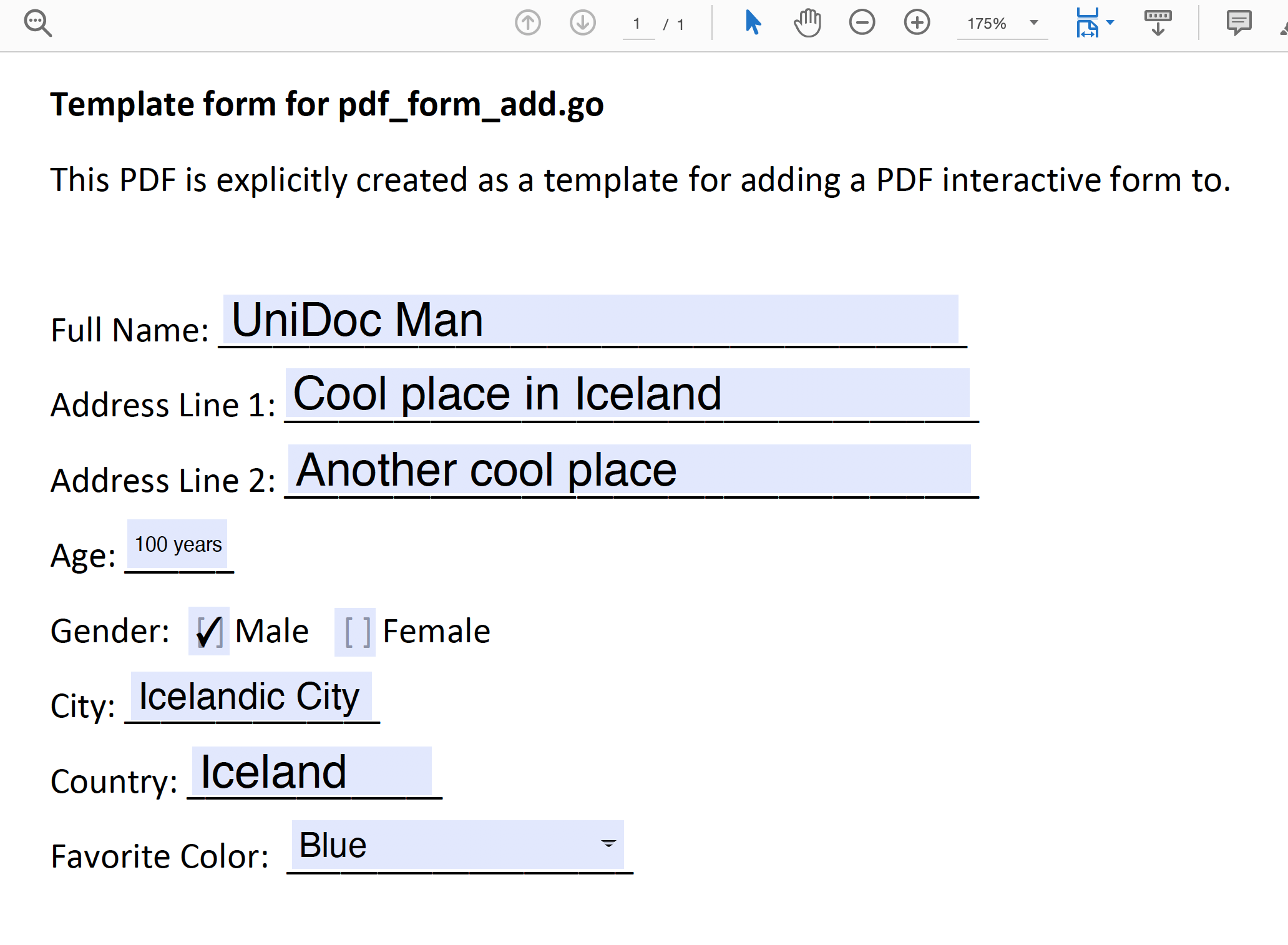
Figure 3: Example of filled PDF form (not flattened).
The full example is shared below which can be run in the UniDoc Playground.
Playground Example - Filling fields with values in PDF form
/*
* Fill PDF form via JSON input data and flatten the output PDF.
*
* Run as: go run pdf_form_fill_json.go input.pdf fill.json [output.pdf].
*/
package main
import (
"fmt"
"os"
"github.com/unidoc/unipdf/v3/annotator"
"github.com/unidoc/unipdf/v3/fjson"
"github.com/unidoc/unipdf/v3/model"
)
// Example of filling PDF formdata with a form.
func main() {
var (
inputPath string
filljsonPath string
outputPath string
)
inputPath = "template1_with_form.pdf"
filljsonPath = "formdata.json"
outputPath = "output.pdf"
// Output path not specified: Export list of fields and data as JSON format.
if len(outputPath) == 0 {
fdata, err := fjson.LoadFromPDFFile(inputPath)
if err != nil {
fmt.Printf("Error: %v\n", err)
os.Exit(1)
}
if fdata == nil {
fmt.Printf("No data\n")
return
}
fjson, err := fdata.JSON()
if err != nil {
fmt.Printf("Error: %v\n", err)
os.Exit(1)
}
fmt.Printf("%s\n", fjson)
return
}
err := fillFields(inputPath, filljsonPath, outputPath)
if err != nil {
fmt.Printf("Error: %v\n", err)
os.Exit(1)
}
fmt.Printf("Success, output written to %s\n", outputPath)
}
// fillFields loads field data from `jsonPath` and used to fill in form data in `inputPath` and outputs
// as PDF in `outputPath`. The output PDF form is flattened.
func fillFields(inputPath, jsonPath, outputPath string) error {
fdata, err := fjson.LoadFromJSONFile(jsonPath)
if err != nil {
return err
}
f, err := os.Open(inputPath)
if err != nil {
return err
}
defer f.Close()
pdfReader, err := model.NewPdfReader(f)
if err != nil {
return err
}
// Populate the form data.
err = pdfReader.AcroForm.Fill(fdata)
if err != nil {
return err
}
// Flatten form.
fieldAppearance := annotator.FieldAppearance{OnlyIfMissing: true, RegenerateTextFields: true}
// NOTE: To customize certain styles try:
// style := fieldAppearance.Style()
// style.CheckmarkGlyph = "a22"
// style.AutoFontSizeFraction = 0.70
// fieldAppearance.SetStyle(style)
//
// or for specifying a full set of appearance styles:
// fieldAppearance.SetStyle(annotator.AppearanceStyle{
// CheckmarkGlyph: "a22",
// AutoFontSizeFraction: 0.70,
// FillColor: model.NewPdfColorDeviceGray(0.8),
// BorderColor: model.NewPdfColorDeviceRGB(1, 0, 0),
// BorderSize: 2.0,
// AllowMK: false,
// })
err = pdfReader.FlattenFields(true, fieldAppearance)
if err != nil {
return err
}
// Generate a PdfWriter instance from existing PdfReader.
pdfWriter, err := pdfReader.ToWriter(nil)
if err != nil {
return err
}
// Write to file.
err = pdfWriter.WriteToFile(outputPath)
return err
}

Once a PDF has been filled, it can still be edited when viewing it in a viewer. In many cases it is desirable to finalize or flatten the values such that they become contents, i.e. inherent part of the PDF that cannot be edited easily.
To illustrate this, we will work with the filled PDF form from above (Figure 3) and flatten the contents to an uneditable PDF. Note, in the section below we will show how to fill and flatten in a single step, which is often desirable.
The code for flattening a filled PDF form is as follows:
pdfReader, f, \_ := model.NewPdfReaderFromFile(inputPath, nil)
defer f.Close()
// Flatten form.
fieldAppearance := annotator.FieldAppearance{
OnlyIfMissing: true,
RegenerateTextFields: true,
}
pdfReader.FlattenFields(true, fieldAppearance)
// Generate a PdfWriter instance from existing PdfReader.
// AcroForm field is no longer needed in the output.
pdfWriter, \_ := pdfReader.ToWriter(&model.ReaderToWriterOpts{
SkipAcroForm: true,
})
// Write the output flattened file.
pdfWriter.WriteToFile(outputPath)
Applying this to the form we filled above (Figure 3), the output is as shown below, where the filled PDF has been flattened (Figure 4). The field appearances have been flattened and are a part of the content and the form/fields are no longer editable. The AcroForm dictionary which normally represents form and fields has been removed also as the information is now only part of the PDF contents like any other parts of the PDF.
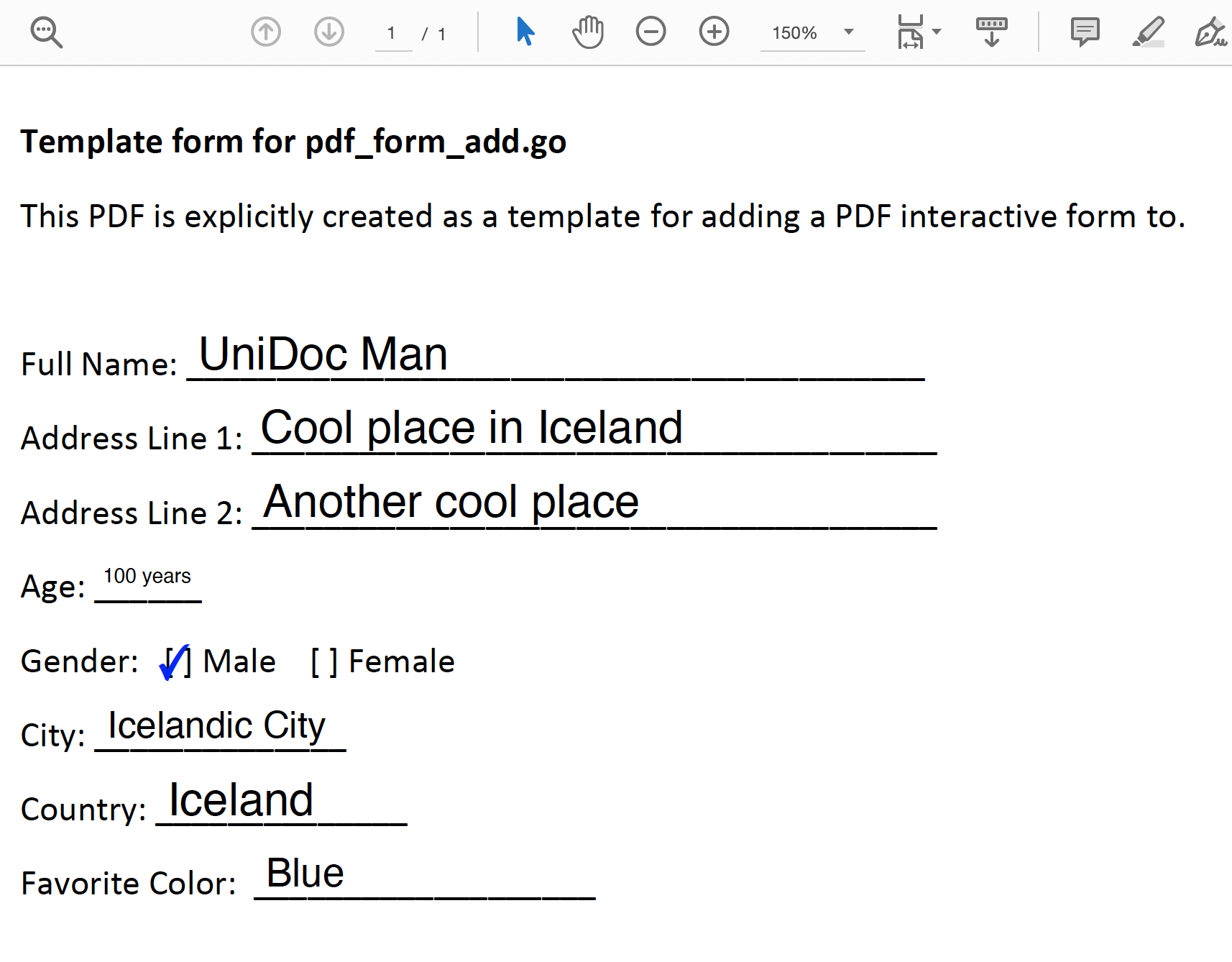
Figure 4: Filled PDF has been flattened and values made part of the content.
The full runnable example for flattening a PDF form is shown below Playground example which can be loaded and run in our Playground.
Filling and Flattening PDF forms in a single step
In the text above, we have covered the cases of creating, filling and flattening PDF forms separately. A common use case is to fill and flatten in a single step. This is usually desirable in applications where a prepared PDF form is to be filled with external information such as filling in customer information.
Another example of how you can use PDF forms to improve your everyday business operations is by using them to collect and document orders, invoices and other engagement documents.
Manually skimming through the data that you collect using PDF forms would be a time-consuming task, which is an inefficient use of your organizational resources. You can use UniPDF to programmatically sift through the data collected using the forms and clean it, process it, and perform meaningful operations on it.
These steps come after you have collected the data. UniPDF can also help you with the data collection stage. You can use the power of the Golang library to convert data from any data source to beautifully crafted PDF reports built using UniPDF’s form builder.
Playground Example - Fill and flatten a PDF form
/*
* Fill PDF form via JSON input data and flatten the output PDF.
*
* Run as: go run pdf_form_fill_json.go input.pdf fill.json [output.pdf].
*/
package main
import (
"fmt"
"os"
"github.com/unidoc/unipdf/v3/annotator"
"github.com/unidoc/unipdf/v3/fjson"
"github.com/unidoc/unipdf/v3/model"
)
// Example of filling PDF formdata with a form.
func main() {
var (
inputPath string
filljsonPath string
outputPath string
)
inputPath = "template1_with_form.pdf"
filljsonPath = "formdata.json"
outputPath = "output.pdf"
// Output path not specified: Export list of fields and data as JSON format.
if len(outputPath) == 0 {
fdata, err := fjson.LoadFromPDFFile(inputPath)
if err != nil {
fmt.Printf("Error: %v\n", err)
os.Exit(1)
}
if fdata == nil {
fmt.Printf("No data\n")
return
}
fjson, err := fdata.JSON()
if err != nil {
fmt.Printf("Error: %v\n", err)
os.Exit(1)
}
fmt.Printf("%s\n", fjson)
return
}
err := fillFields(inputPath, filljsonPath, outputPath)
if err != nil {
fmt.Printf("Error: %v\n", err)
os.Exit(1)
}
fmt.Printf("Success, output written to %s\n", outputPath)
}
// fillFields loads field data from `jsonPath` and used to fill in form data in `inputPath` and outputs
// as PDF in `outputPath`. The output PDF form is flattened.
func fillFields(inputPath, jsonPath, outputPath string) error {
fdata, err := fjson.LoadFromJSONFile(jsonPath)
if err != nil {
return err
}
f, err := os.Open(inputPath)
if err != nil {
return err
}
defer f.Close()
pdfReader, err := model.NewPdfReader(f)
if err != nil {
return err
}
// Populate the form data.
err = pdfReader.AcroForm.Fill(fdata)
if err != nil {
return err
}
// Flatten form.
fieldAppearance := annotator.FieldAppearance{OnlyIfMissing: true, RegenerateTextFields: true}
// NOTE: To customize certain styles try:
// style := fieldAppearance.Style()
// style.CheckmarkGlyph = "a22"
// style.AutoFontSizeFraction = 0.70
// fieldAppearance.SetStyle(style)
//
// or for specifying a full set of appearance styles:
// fieldAppearance.SetStyle(annotator.AppearanceStyle{
// CheckmarkGlyph: "a22",
// AutoFontSizeFraction: 0.70,
// FillColor: model.NewPdfColorDeviceGray(0.8),
// BorderColor: model.NewPdfColorDeviceRGB(1, 0, 0),
// BorderSize: 2.0,
// AllowMK: false,
// })
err = pdfReader.FlattenFields(true, fieldAppearance)
if err != nil {
return err
}
// Generate a PdfWriter instance from existing PdfReader.
pdfWriter, err := pdfReader.ToWriter(nil)
if err != nil {
return err
}
// Write to file.
err = pdfWriter.WriteToFile(outputPath)
return err
}
Special cases
There are many special cases that can come up with regard to PDF form handling. Here we will go through a few of them in the form of questions.
How can I use custom fonts when filling and flattening forms?
To use custom fonts when filling and flattening forms in UniPDF, you can specify the font to be used when filling out the form fields. This is especially useful when working with non-Latin characters, symbolic CJK (Chinese, Japanese, Korean) fonts, unicode characters, or special symbols that are not supported by the default fonts included with PDF documents.
PDF documents come with a set of 14 standard fonts known as the “PDF Core Fonts” that are guaranteed to be available on all PDF viewers and devices. While these fonts cover a wide range of Latin characters and some basic symbols, they may not provide support for all possible characters and glyphs. In cases where the form data includes characters or glyphs that are not included in the PDF Core Fonts, specifying custom fonts may be necessary to ensure accurate display.
By embedding custom fonts in your PDF document and specifying them when filling out a form, you can ensure that the form data appears consistent with the rest of the document and displays accurately, even when using non-standard characters or glyphs.
The pdf_form_fill_custom_font.go example code file in UniPDF demonstrates how to specify custom fonts when filling and flattening PDF forms. By using this example, you can learn how to load and embed custom fonts in a PDF document, as well as how to specify them when filling out a form.
How can I merge FDF form data with a template PDF and produce a flattened output PDF?
FDF stands for “Forms Data Format”, and it is a file format used for representing form data in PDF documents. FDF files typically contain key-value pairs that represent the field names and values of the form data.
When filling out a PDF form programmatically, you need a way to specify the values of the form fields. FDF files provide a convenient way to do this, as they allow you to separate the form data from the PDF document itself. This means that you can keep the PDF document as a template and fill in the form data separately, which can be especially useful if you need to fill out multiple copies of the same form with different data.
UniPDF allows you to merge FDF form data with a template PDF and produce a flattened output PDF. The pdf_form_fill_fdf_merge.go example code file demonstrates how to do this in UniPDF. By using this example, you can learn how to generate appearance streams and produce a flattened output PDF that includes the merged form data.
How can I export form data as JSON using UniPDF?
You can use the pdf_form_list_fields.go example in https://github.com/unidoc/unipdf-examples/tree/master/forms.
By default it lists all fields and their values in JSON output format.
How can I control the font size ?
The pdf_form_fill_custom_font.go example can also be used to change the font size. This can be done
simply by setting the Size property and hardcoding it to a desired value.
Conclusion
You can use UniPDF to build beautifully crafted PDF forms through which you can gather information from your users. These forms can be shared and archived to maintain structured records of sales, queries and other engagement processes.
With the help of UniPDF, this process can be streamlined and you can use the library in many ways to improve the efficiency of your office tasks.
UniDoc is constantly improving its libraries based on customer feedback, if you want a feature included in the library, feel free to open a ticket on UniDoc’s GitHub, where you can also check out a whole repository of examples, built to get you started using UniDoc. You can also contact us with any inquiries.
Sign up for free and get started with PDF forms in UniDoc.