Why AI-Generated Code Cannot Replace a Trusted Go Vendor

AI-generated code in enterprise Go environments is a real topic in engineering teams right now. Tools like GitHub Copilot and Claude Code make it possible to generate working Go code in seconds. For many tasks, that speed is useful.
But for enterprise document workflows where a broken PDF means a failed audit or a corrupted patient record, speed and trustworthiness are different things. This article explains the specific gap between what AI code generation produces and what a commercially maintained Go library provides.
What AI-Generated Go Code Actually Produces
AI coding tools generate code based on patterns from large repositories. They produce code that compiles, passes obvious tests, and looks professional on first read. The problem is what they miss.
A study published at the USENIX Security Symposium 2025 analyzed 576,000 code samples across 16 LLMs and found that nearly 20% of recommended packages did not exist. Attackers register those hallucinated names with malicious packages and wait for developers to install them — a supply chain attack researchers have named “slopsquatting.” Senior Go practitioners have raised the same concern from a different angle, with many saying they do not want to maintain AI-generated code because the risk surface is too hard to reason about after the fact.
Why Document Processing Is the Wrong Place to Trust AI Code
The PDF specification runs to over 1,000 pages. Real-world documents routinely violate it.
Files arrive from legacy enterprise systems generating non-compliant output for fifteen years, scanner firmware with incomplete spec implementations, and government forms created before the spec was finalized. A library that has only seen well-formed test files fails on these. The failure is not always immediate. A fix that handles a font encoding issue in one document type can silently corrupt a completely different code path used by another document structure, surfacing three weeks later in production.
No amount of AI iteration addresses this. Edge case coverage accumulates through years of production exposure across real enterprise documents, not through generating more code. This is the same reason handling corrupted or malformed PDFs in Go pipelines requires more than a clean parser. It requires having seen the documents.
The Accountability Gap AI Cannot Fill
When AI-assisted open-source code fails in production, there is no one to call. Under the EU Cyber Resilience Act, DORA, and US federal procurement guidance, enterprises are increasingly expected to identify a responsible economic operator behind each component in their software supply chain. An SBOM can list an open-source repository, but listing alone does not establish who is accountable when that component fails.
A GitHub URL is not a vendor. It has no legal identity, no commercial obligations, and no SLA when something breaks at 2am in a regulated workflow.
What the Supply Chain History Tells Us
The XZ Utils incident in March 2024 is the clearest illustration. An unknown attacker spent two years submitting legitimate contributions to a single-maintainer open-source library before planting a sophisticated backdoor, hidden in obfuscated build scripts and binary test fixtures rather than readable source. The code was nominally public, but the malicious payload only surfaced when a Microsoft engineer noticed unusual CPU usage and slow SSH logins — and by then the compromised release was already propagating through distributions.
Log4j is the same pattern from a different angle. Three years after the critical vulnerability was disclosed, roughly 13% of Log4j downloads were still of the vulnerable version according to Sonatype’s State of the Software Supply Chain report. No SLA. No commercial accountability. No guaranteed response.
For Go teams choosing a document library, the question is not whether their chosen library could have this problem. It is what the vendor does to prevent it. UniDoc tracks every disclosed vulnerability publicly at security.unidoc.io, with automated scanning on every release.
What Human Review Changes
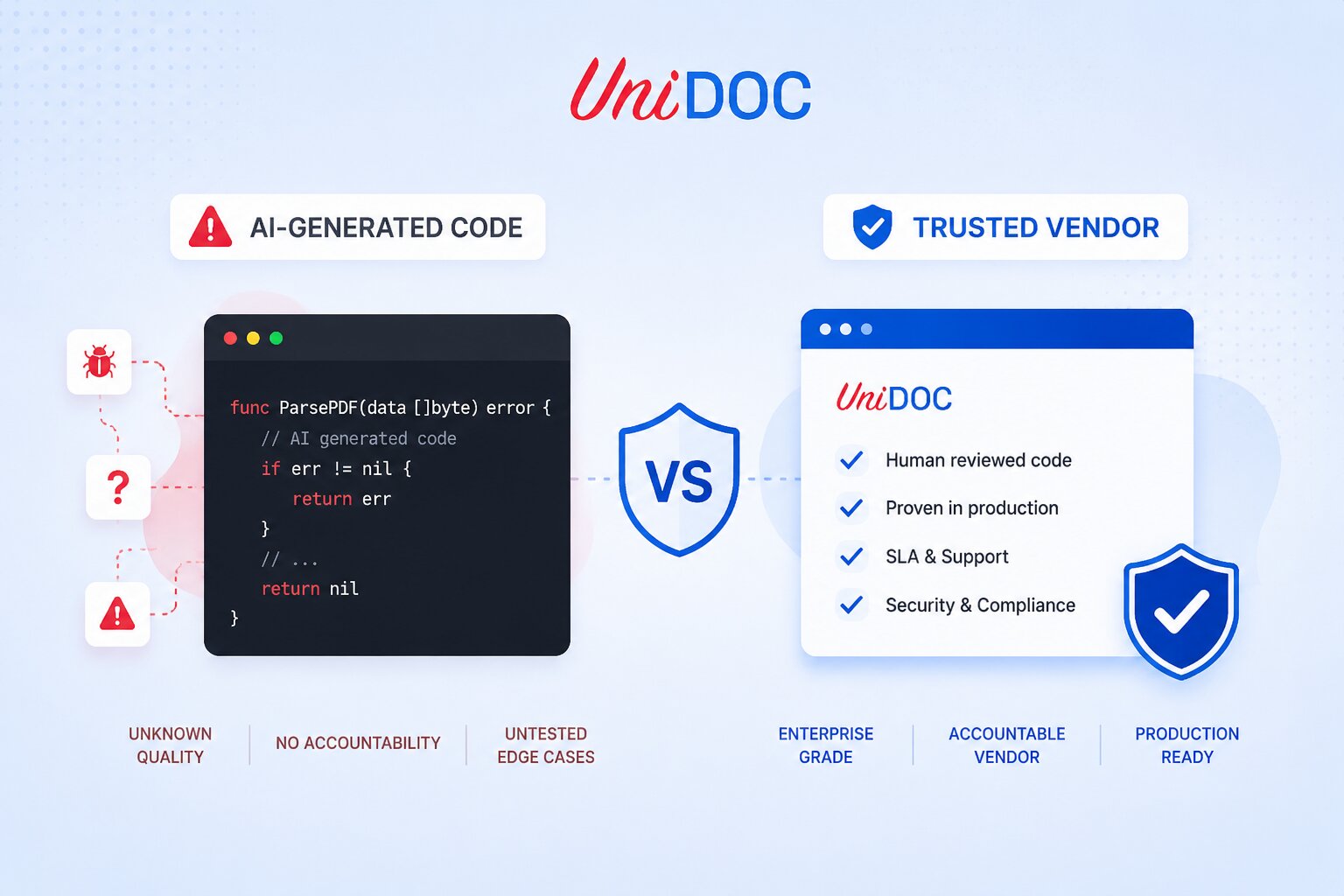
UniDoc uses AI coding tools. That sounds contradictory to the concerns raised above, but the difference is not whether AI is involved — it is what happens between the AI’s output and the released binary.
Every line goes through human review before it ships. An engineer reads it, understands the consequence surface, verifies it against the spec, and takes named responsibility. The AI produces a draft. A human decides whether it ships. UniDoc’s conformance with ETSI EN 319 142 (PAdES) provides independent third-party verification that its digital signature handling meets the European standards required for eIDAS-grade workflows.
For document libraries specifically, this matters because a change that fixes one document type correctly can interact with a completely different code path for another document structure. Understanding whether that change is safe requires knowing the codebase deeply, not just whether it passes the test for the file that triggered the bug.
What Enterprise Teams Should Actually Ask
When evaluating any Go PDF library for production:
- Who reviews the code before it ships, and is that process verifiable?
- Is there a public CVE tracking page with documented response SLAs?
- Can the vendor be named in a software bill of materials?
- How minimal and auditable is the dependency tree?
- How long has the library been in real production with real enterprise documents?
A library that cannot answer these clearly is not a production-grade choice when document failure creates legal, financial, or compliance consequences.
Further Reading
For Go teams evaluating production document workflows, these articles cover related decisions in depth:
- How to Handle Corrupted or Malformed PDFs in Go Pipelines — recovery patterns that only come from real-world edge case coverage
- 5 Key Benefits of Using Go for Document Automation — the architectural case for a pure Go document stack
- Golang PDF Library Guide: How to Choose the Right One? — a structured evaluation framework
- Applying Digital Signature to Your PDF — compliance-grade signing and validation
Conclusion
AI-generated code in enterprise Go is not the problem. Using it without accountability is.
For enterprise document workflows where failure creates real consequences, the question is not whether AI can write the code. It is whether anyone is accountable when the edge case hits.
UniPDF is a pure Go library built and maintained by a named commercial vendor since 2016, with human-reviewed code, automated CVE scanning on every release at security.unidoc.io, and nearly a decade of real-world edge case coverage across Fortune 500 teams in regulated industries. It deploys as part of your Go binary with no JVM, no native binary, and no external dependencies.
Start evaluating UniPDF for your production workflow. Request a free trial at unidoc.io or explore pricing and licensing options.
Frequently Asked Questions
Can AI-generated code be used safely in enterprise Go applications?
Yes, when a human engineer reads every line, understands the consequence surface, and takes named accountability for what ships. The risk is AI-generated code that reaches production without that review.
What is vibe coding and why does it matter for production systems?
Vibe coding means accepting AI output, seeing it pass basic tests, and shipping without deeply understanding the code. In document processing, this breaks when the library encounters real-world files that differ from the test samples used during development.
What should I look for when evaluating a Go PDF library for enterprise use?
Ask who reviews the code before it ships, whether there is a public CVE process with response SLAs, whether the vendor can be named in an SBOM, and what the support path is when something breaks in production.
What is an SBOM and why does it matter?
A Software Bill of Materials lists every component a product depends on, who maintains it, and whether it has known vulnerabilities. Regulations including the EU Cyber Resilience Act and US federal requirements now make SBOM-ready vendor identity a purchasing requirement.
What was the XZ Utils backdoor?
In March 2024, an unknown attacker spent two years building trust in a single-maintainer open-source library before planting a backdoor capable of remote system access. It was discovered almost by accident. The library was fully public and readable throughout.
Why does edge case coverage matter more than code volume?
Real enterprise documents violate the PDF spec in ways that only show up in production. A library accumulates handling for those variations through years of exposure across real customers, not through generating more code. That coverage cannot be shortcut.